Геораспределённое облако AccentOS OpenStack¶
1.3 Рекомендации по выбору архитектуры AccentOS для геораспределенных облаков 5.13 Функционал синхронной и асинхронной репликации между SDS на разных площадках
Введение¶
Облако OpenStack и AccentOS динамично развиваются благодаря сообществу OpenStack, Ceph, Linux, а также компаниям RedHat, IBM, Oracle, Mirantis и множеству других, что даёт всё новые варианты реализации облачной архитектуры. Например, появление стабильной версии Ceph 20.2 в конце апреля 2026 г. дало новый импульс к развитию распределённой архитектуры AccentOS. Для того чтобы быть в курсе последних событий, в конце документа прилагаются рекомендуемые ссылки.
Архитектуры распределённого облака¶
При разворачивании облака с большим количеством сайтов, расположенных на значительном удалении, требуется выбрать архитектуру, которая лучше всего подходит для конкретной реализации.
Компаниям с крупными филиалами (банки, ритейлеры, госуслуги, операторы связи) требуется одновременно:
- Низкая задержка приложений для обслуживания систем или клиентов в разных локациях на расстоянии несколько тысяч километров.
- Отказоустойчивость — сбой в ЦОДе локации 1 должен перенести задачи из локации 1 в локацию 2 и не должен создать блокировку для выполнения задач локации 2.
Решение AccentOS имеет иерархическую архитектуру для централизованного управления неограниченным количеством сайтов в разных географических локациях. Отличия работы заключаются в требованиях Заказчика и внешних ограничениях (тип приложений, механизмы синхронизации данных, расстояния и время задержки между локациями, скорость СХД, время задержки самих приложений и проч.). Описать все факторы и дать оптимальное решение — предмет проектирования, а не общего формального описания. Тем не менее, очевидные факторы (тип приложения, тип СХД, расстояния) могут ограничить варианты выбираемых архитектур.
Основные варианты архитектуры¶
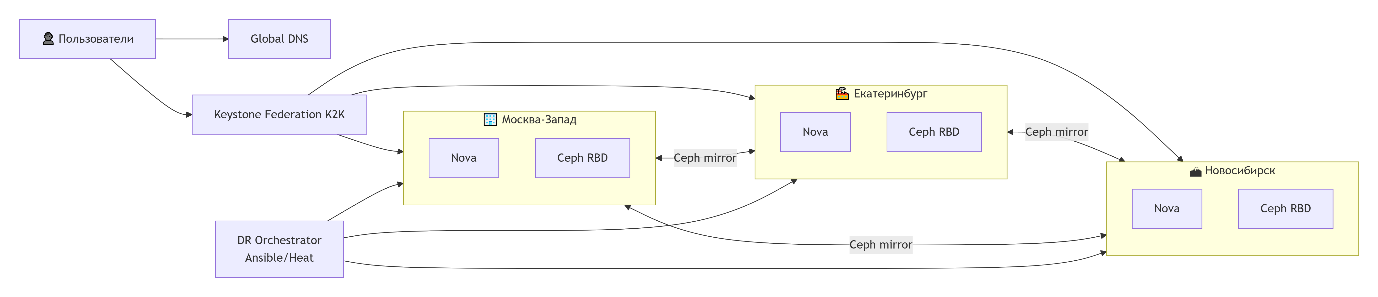
Изолированные регионы (Federated Model) – предпочтительный вариант. Каждый регион имеет собственные сервисы (Nova, Neutron, Cinder) и свою БД. Регионы связаны только через федерацию идентификации (Keystone).
Stretched / Shared – одна система управления на несколько ЦОД. Сложно, требует низкой задержки. Не рекомендуется при больших расстояниях.
Наш опыт реализации подобного проекта: облако для РТК ЦОД, в рамках трёх ЦОД в городе Москва (М9-М10-Остаповский), с плечом около 70 км в режиме FT для СХД и ONAP (слоя управляющих контроллеров).
Подход к проектированию распределённого облака¶
Основной подход при выборе архитектуры – синхронная репликация в режиме только тех данных, которые действительно требуют актуальности; для остальных данных (особенно больших) нужно выполнять зеркалирование в асинхронном режиме в допустимое время.
Соответственно, каждый удалённый регион, локация должны иметь отдельную локальную систему управления (control plane) для управления локальными ресурсами, данными и сервисами, а общие глобальные ресурсы и сервисы (идентификация и образы) должны реплицироваться в соответствии с их размерами и важностью.
В частности, данные идентификации и авторизации пользователей, RBAC, которые имеют небольшой размер, не требуют моментального времени реакции, редко обновляются, могут синхронизироваться в реальном времени и кешироваться локально.
У AccentOS / OpenStack функция идентификации может выполняться с помощью внешних зрелых инструментов – LDAP (MS AD, Free IPA), которые имеют собственные механизмы доставки и кеширования информации.
Функция авторизации, которая часто используется в control plane (RBAC), должна выполняться централизованно и локально кешироваться, так как смена политик RBAC происходит очень редко.
Функции очередей, работы с СУБД, журналирования, резервного копирования, мониторинга, обработки аналитики должны выполняться локально с предоставлением удалённого доступа через WEB (или терминальный протокол) для режима централизованного обслуживания и для локальных администраторов сайтов облака.
Примеры реализации архитектур¶
Федерация идентификации (Keystone) Пользователь в Москве должен один раз войти и получить доступ к ресурсам во Владивостоке.
Две модели:
- Keystone-в-Keystone (K2K) – регион «Москва» доверяет региону «Новосибирск». Пользователь из Москвы получает токен для Новосибирска без повторного ввода пароля.
- Внешний IdP (SAML/OIDC) – общий корпоративный провайдер (например, Keycloak на базе AD). Ответственность за обеспечение сервиса перекладывается на AD. С точки зрения AccentOS так проще, ответственность за надёжность, скорость и качество на другой службе Заказчика.
Плюсы федерации: - Автоматическое создание пользователей в регионе при первом входе. - Сбой Keystone в ЦОД «Москва» не влияет на ЦОД «Владивосток».
Рекомендация: использовать K2K или внешний IdP, но НЕ реплицировать БД Keystone синхронно через магистральные каналы (высокая задержка).
Репликация образов (Glance)
Образы ВМ (Linux, Windows, Astra Linux) должны быть локально доступны в каждом регионе.
Способы:
- Ceph RBD mirroring – асинхронная репликация между Ceph-кластерами регионов «Москва» и «Санкт-Петербург» в режиме EC (строго объектное тип хранения).
- Multi-store Glance – один образ хранится в нескольких ЦОД. Занимает больше места, но прост (можно использовать дополнительный модуль AppLevel в качестве источника и системы управления образами).
Пример: оператор связи с ЦОД в Москве, Екатеринбурге и Новосибирске загружает образ один раз, и он предоставляется во все регионы сразу.
Синхронизация БД и состояния
- Nova, Neutron, Cinder – БД остаются локальными (виртуальные машины в Москве не мигрируют в Екатеринбург автоматически).
- Keystone – либо федерация, либо Galera Cluster через ВОЛС (только если сеть очень быстрая, менее 10 мс).
- RabbitMQ – свои кластеры в каждом ЦОД.
Вывод: не пытайтесь реплицировать все БД. Только Keystone (и то с осторожностью) – остальное локально.
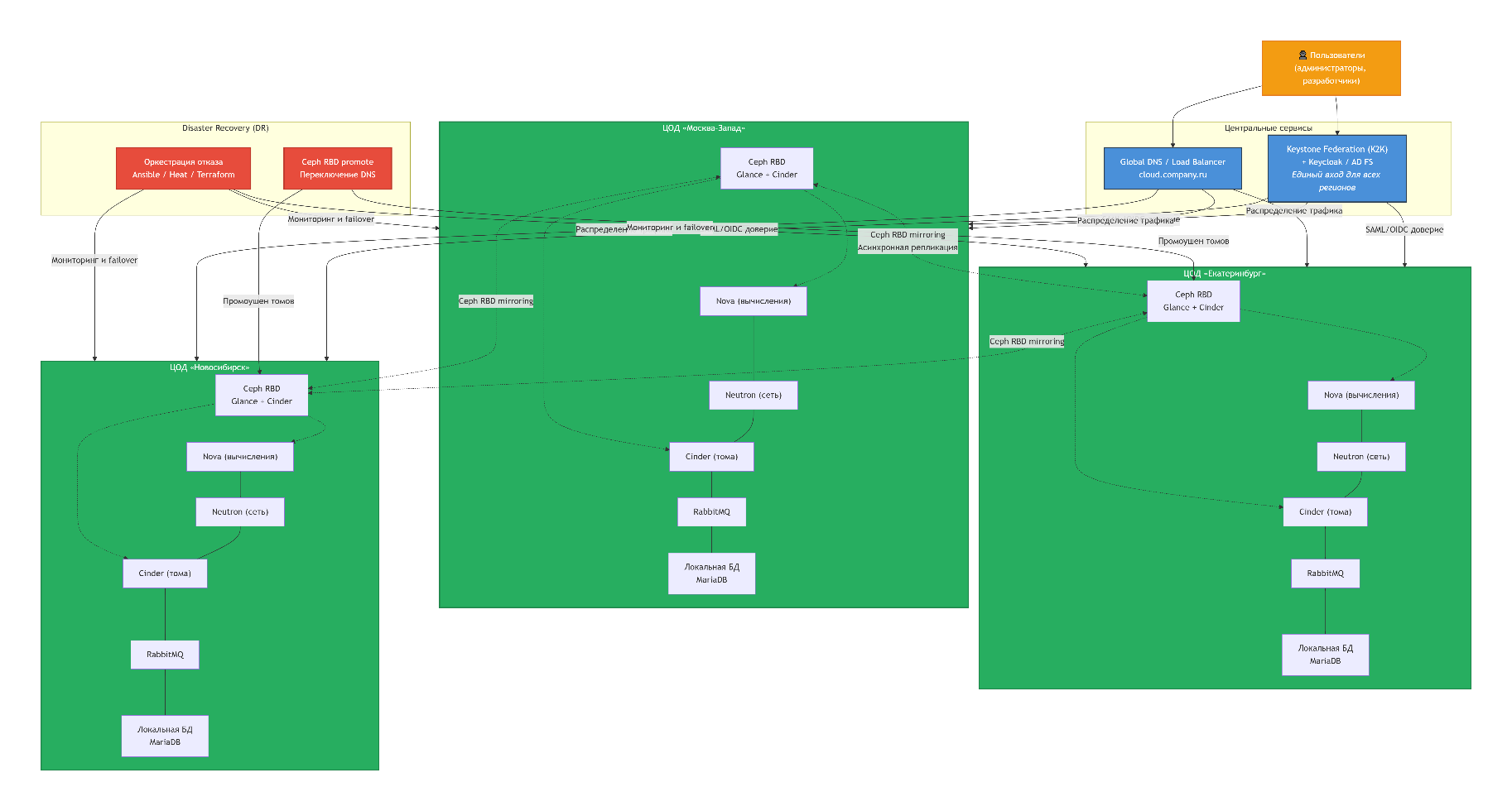
Disaster Recovery (DR)
Пример: головной ЦОД «Москва-Запад» и резервный ЦОД «Нижний Новгород».
Ключевые компоненты: - Активно-пассивный режим – Москва работает, Нижний Новгород ждёт. - Репликация критических данных: образы (Glance) и блочные тома (Cinder) через
Ceph RBD mirroring.
- Оркестрация отказа: Ansible и Heat.
Сценарий отказа ЦОД «Москва-Запад»: 1. Продвинуть зеркала Ceph в ЦОД «Нижний Новгород» (
rbd mirror promote). 2. Запустить контейнеры OpenStack (Kolla) в Нижнем Новгороде. 3. Выполнить Heat-шаблоны для воссоздания ВМ. 4. Сменить DNS (например,cloud.company.ruна IP Нижнего Новгорода).Важно: ВМ пересоздаются заново, а не мигрируются – это проще и надёжнее.
Инструменты с открытым исходным кодом
Задача Инструменты Федерация Keystone K2K (SAML/OIDC), Keycloak Репликация образов/томов Ceph RBD mirroring, Glance multi-store Базы данных MariaDB Galera Балансировка нагрузки HAProxy Оркестрация отказа Ansible и Heat
Централизованное управление распределённым облаком¶
Централизованная работа с несколькими VIM из единого интерфейса возможна в составе Horizon для управления существующими VIM, запуска новых VIM и выделения ресурсов в составе развёрнутого сайта.
Централизованная автоматизация может иметь разную специфику, когда предсказать объём передаваемых данных не представляется возможным. Если автоматизация связана с RBAC, то она будет применяться синхронно на всех сайтах. Если она сопряжена с большими данными (резервное копирование, образы и проч.), то централизованное управление может выполняться после зеркалирования требуемых для автоматизации данных.
Такие данные, как журналирование, аналитика, мониторинг, должны сохраняться локально. Это касается и приложений, которые эти данные обрабатывают. Доступ к приложениям обработки данных может выполняться через централизованную консоль в режиме WEB или с помощью терминального протокола.
Рекомендации¶
Основные рекомендации при реализации облака для multi-region архитектуры:
- Keystone федеративная, не реплицировать на большие расстояния (задержки более 30 мс).
- Образы и тома реплицировать асинхронно (Ceph mirroring).
- Nova, Neutron, Cinder – локальны в каждом ЦОД.
- DR с использованием автоматизации (Ansible/Heat).
- Тестирование отказов региона в песочнице перед внедрением.
- Учёт реальной пропускной способности и времени задержки между ЦОДами.
Рекомендуемые ссылки¶
- https://wiki.openstack.org/wiki/Keystone_edge_architectures
- https://docs.openstack.org/keystone/2023.2/getting-started/architecture.html
- https://docs.openstack.org/keystone/latest/admin/federation/configure_federation.html
- https://docs.redhat.com/en/documentation/red_hat_openstack_platform/17.1/html-single/integrating_openstack_identity_with_external_user_management_services/index
- https://openmetal.io/resources/blog/how-to-integrate-active-directory-with-openstack-for-user-management/
- https://openmetal.io/resources/blog/building-multi-site-high-availability-infrastructure-with-openmetal/
- https://www.linkedin.com/pulse/designing-multi-region-openstack-clouds-federation-dr-ahmad-ullah-m2ttf/
- https://cloudification.io/cloud-blog/mastering-openstack-multitenancy-with-keystone-and-neutron-rbac-a-guide-to-secure-collaboration/
- https://docs.ceph.com/en/latest/cephadm/install/
- https://docs.redhat.com/en/documentation/red_hat_ceph_storage/5/html/dashboard_guide/management-of-pools-on-the-ceph-dashboard
- https://docs.redhat.com/en/documentation/red_hat_ceph_storage/7/html/dashboard_guide/ceph-dashboard-installation-and-access
- https://www.ibm.com/support/pages/ceph-scrubbing-and-its-parameters
- https://docs.ceph.com/en/latest/rados/configuration/osd-config-ref/
- https://oneuptime.com/blog/post/2026-03-31-rook-ceph-data-scrubbing/view
- https://oneuptime.com/blog/post/2026-03-31-rook-end-to-end-data-integrity-checks/view
- https://habr.com/ru/companies/runity/articles/921288/
- https://firstcloud.pl/blog/openstack-multi-datacenter-deployment-strategies/
- https://habr.com/ru/companies/runity/articles/926040/
- https://habr.com/ru/companies/runity/articles/929514/
- https://ithub.uno/statiarticles/9_infrastructure/ceph-%D1%87%D0%B0%D1%81%D1%82%D1%8C-1-ceph-%D0%B4%D0%BB%D1%8F-%D0%B2%D0%B7%D1%80%D0%BE%D1%81%D0%BB%D1%8B%D1%85-%D1%87%D1%82%D0%BE-%D1%8D%D1%82%D0%BE-%D1%82%D0%B0%D0%BA%D0%BE%D0%B5-%D0%BA%D0%B0%D0%BA-%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%B0%D0%B5%D1%82-%D0%B8-%D0%B7%D0%B0%D1%87%D0%B5%D0%BC-%D0%B2%D0%B0%D0%BC-%D1%8D%D1%82%D0%BE-%D0%BD%D1%83%D0%B6%D0%BD%D0%BE-r52/
- https://ithub.uno/statiarticles/9_infrastructure/ceph-%D1%87%D0%B0%D1%81%D1%82%D1%8C-2-%D1%80%D0%B0%D0%B7%D0%B2%D0%BE%D1%80%D0%B0%D1%87%D0%B8%D0%B2%D0%B0%D0%B5%D0%BC-ceph-tentacle-%D1%81-%D0%BD%D1%83%D0%BB%D1%8F-%D0%BE%D1%82-%D1%87%D0%B8%D1%81%D1%82%D1%8B%D1%85-%D1%81%D0%B5%D1%80%D0%B2%D0%B5%D1%80%D0%BE%D0%B2-%D0%B4%D0%BE-%D1%80%D0%B0%D0%B1%D0%BE%D1%87%D0%B5%D0%B3%D0%BE-%D0%BA%D0%BB%D0%B0%D1%81%D1%82%D0%B5%D1%80%D0%B0-r55/
- https://ithub.uno/statiarticles/9_infrastructure/ceph-%D1%87%D0%B0%D1%81%D1%82%D1%8C-3-ceph-%D0%B2-%D0%BF%D1%80%D0%BE%D0%B4%D0%B0%D0%BA%D1%88%D0%BD%D0%B5-%D1%82%D1%8E%D0%BD%D0%B8%D0%BD%D0%B3-%D0%B0%D0%BF%D0%B3%D1%80%D0%B5%D0%B9%D0%B4-%D0%B4%D0%BE-tentacle-%D0%B8-%D0%B2%D0%BE%D1%81%D1%81%D1%82%D0%B0%D0%BD%D0%BE%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5-%D0%BF%D0%BE%D1%81%D0%BB%D0%B5-%D0%BA%D0%B0%D1%82%D0%B0%D1%81%D1%82%D1%80%D0%BE%D1%84-r58/
- https://docs.ceph.com/en/squid/rados/configuration/network-config-ref/
- https://docs.ceph.com/en/tentacle/rados/configuration/osd-config-ref/#dmclock-qos
- https://docs.ceph.com/en/reef/rados/configuration/mclock-config-ref/
- https://community.ibm.com/community/user/blogs/daniel-alexander-parkes/2025/04/15/getting-started-with-ibm-storage-ceph-multisite-re
- https://ceph-stretched-cluster-series.hashnode.dev/getting-started-with-ibm-storage-ceph-multisite-replication
- https://community.ibm.com/community/user/blogs/daniel-alexander-parkes/2025/04/15/part-2-streched-cluster-ceph
- https://community.ibm.com/community/user/blogs/daniel-alexander-parkes/2025/04/15/part-3-surviving-datacenter-failures-ceph
- https://slurm.io/blog/ceph-data-recovery-and-relocation
- https://slurm.io/blog/ekspluatatsiya-ceph