Растянутые кластеры Stretch clusters Ceph¶
5.12 Функционал георезервирования в конфигурации active/active между кластерами на разных площадках, соединенных по L3-сети, раундтрип между площадками - до 50 мс. Количество кластеров, объединенных в георезерв - до 4¶
5.13 Функционал синхронной и асинхронной репликации между SDS на разных площадках¶
Ключевые понятия .. image:: _static/stretch_key_concepts.png
alt: Ключевые понятия растянутых кластеров Ceph width: 600px align: center
Введение¶
При рассмотрении вопросов репликации, аварийного восстановления и резервного копирования и восстановления данных мы выбираем из множества стратегий с различными уровнями SLA для восстановления данных и приложений. Ключевыми факторами являются целевое время восстановления (RTO) и целевая точка восстановления (RPO). Синхронная репликация обеспечивает наименьшее значение RPO, что означает нулевую потерю данных. Ceph может реализовать синхронную репликацию между площадками, распределяя кластер Ceph по нескольким центрам обработки данных. Асинхронная репликация по своей сути подразумевает ненулевое значение RPO (Return One Point). В Ceph асинхронная многосайтовая репликация включает в себя репликацию данных в другой кластер Ceph. Для каждого метода доступа к хранилищу Ceph (объектный, блочный и файловый) на уровне сервиса реализован свой собственный метод асинхронной репликации. .. image:: _static/async_vs_sync_replication.png
alt: Сравнение асинхронной и синхронной репликации width: 600px align: center
Асинхронная репликация : Репликация происходит на уровне сервисов (RBD, CephFS или RGW), как правило, между полностью независимыми кластерами Ceph. Синхронная репликация («Расширенный кластер») : репликация выполняется на уровне RADOS (кластера), поэтому операции записи должны быть завершены на каждом узле, прежде чем подтверждение будет отправлено клиентам. Оба метода имеют свои преимущества и недостатки, а также разные профили производительности и особенности восстановления. Прежде чем подробно обсуждать кластеры Ceph-последовательностей, рассмотрим краткий обзор этих режимов репликации.
Параметры репликации в Ceph¶
Асинхронная репликация¶
Асинхронная репликация осуществляется на уровне сервисов. На каждом узле создается полноценный автономный кластер Ceph, который поддерживает независимые копии данных.
- RGW Multisite : Каждый сайт развертывает одну или несколько независимых зон RGW. Изменения распространяются асинхронно между сайтами с использованием структуры репликации RGW multisite. Эта репликация не основана на журнале. Вместо этого она основана на лог-репликации, где каждый RGW отслеживает изменения с помощью журнала операций (журналов синхронизации), и эти журналы воспроизводятся на других сайтах для репликации данных.
- Зеркалирование RBD : данные блоков зеркалируются либо с использованием журнального подхода (как в Openstack), либо с использованием моментальных снимков (как в ODF/OCP), в зависимости от ваших требований к производительности, согласованности при сбоях и планированию.
- Функция зеркального отображения снимков CephFS (в активной разработке): использует снимки для репликации файловых данных с настраиваемыми интервалами.
Асинхронная репликация хорошо подходит для архитектур со значительной задержкой в сети между узлами. Такой подход позволяет приложениям продолжать работу, не дожидаясь завершения удаленной записи. Однако важно отметить, что эта стратегия по своей сути предполагает ненулевое значение целевой точки восстановления (RPO), что означает некоторую задержку до того, как удаленные узлы станут согласованными с основным. В результате сбой узла может привести к потере недавно записанных данных, которые все еще находятся в процессе передачи. Чтобы ознакомиться с асинхронной репликацией Ceph, прочитайте наши предыдущие статьи в блоге: Многосайтовая репликация объектного хранилища .
Синхронная репликация: растянутый кластер¶
Растянутый кластер — это единый кластер Ceph, развернутый в нескольких центрах обработки данных или зонах доступности. Операции записи возвращаются клиентам только после того, как данные сохраняются на всех площадках или на достаточном количестве площадок для удовлетворения требований схемы репликации каждого логического пула. Это обеспечивает:
- RPO = 0 : Отсутствие потери данных при отказе одного из сайтов, поскольку каждая операция записи клиента синхронно реплицируется и будет воспроизведена после восстановления работы отказавшего сайта.
- Управление единым кластером : специальная конфигурация репликации на стороне клиента не требуется: используются стандартные инструменты и рабочие процессы Ceph.
Растянутый кластер предъявляет строгие требования к сети: максимальное время отклика (RTT) между узлами составляет 10 мс. Поскольку данные для записи в OSD должны передаваться между узлами до того, как клиенту будет отправлено подтверждение, задержка имеет критическое значение. Нестабильность сети, недостаточная пропускная способность и скачки задержки могут ухудшить производительность и поставить под угрозу целостность данных.
Кластеры Ceph Stretch¶
Введение¶
Расширяемые кластеры Ceph обладают преимуществами, которые делают их хорошим вариантом для критически важных приложений, требующих максимальной бесперебойной работы и отказоустойчивости:
- Отказоустойчивость : распределенный кластер прозрачно обрабатывает отказ всей площадки, не влияя на работу клиентов. Он может выдержать отказ обеих площадок без потери данных.
- Строгая согласованность: в конфигурации с тремя площадками данные, загруженные онлайн, мгновенно становятся видимыми и доступными для всех зон доступности/площадок. Строгая согласованность позволяет клиентам на каждой площадке всегда видеть самые актуальные данные.
- Простая настройка и работа со второго дня: Одно из главных преимуществ кластеров с расширенными ресурсами — простота в эксплуатации. Во многом они похожи на стандартные кластеры с одним узлом. Кроме того, для восстановления после сбоя узла не требуется ручного вмешательства, что упрощает управление и развертывание.
- Растянутые кластеры могут быть дополнены многосайтовой асинхронной репликацией для межрегиональной передачи данных.
Однако крайне важно учитывать ограничения, связанные с кластерами Ceph-последовательностей:
- Сетевое взаимодействие имеет решающее значение : недостатки межсайтовой сети, включая нестабильность, скачки задержки и недостаточную пропускную способность, влияют на производительность и целостность данных.
- Производительность : Задержка операций записи увеличивается на величину RTT двух наиболее удаленных площадок. При развертывании на трех площадках стратегию защиты данных пула следует настроить для репликации со значением
size6, что означает усиление записи на шесть операций OSD на каждую операцию записи клиента. Необходимо соответствующим образом установить ожидания относительно рабочей нагрузки. Например, рабочая нагрузка базы данных OLTP с высокой производительностью ввода-вывода в секунду и низкой задержкой, вероятно, будет испытывать трудности при хранении данных в растянутом кластере. - Для обеспечения надежности рекомендуется использовать реплику 6 (или реплику 4 с расширением на две площадки) : мы храним шесть (или четыре) копии данных. В настоящее время кодирование с исправлением ошибок недоступно из-за влияния на производительность, требований к межсайтовой сети и нюансов обеспечения одновременной строгой согласованности и высокой доступности. Это, в свою очередь, означает, что общий доступный объем используемой емкости для заданного объема базового хранилища должен тщательно оцениваться по сравнению с обычным односайтовым кластером.
- Единый кластер для всех площадок : если данные повреждены из-за программной ошибки или ошибки пользователя, включая удаление данных в едином кластере, это повлияет на данные, доступные всем площадкам.
Сетевое взаимодействие: Основа кластера с расширенными возможностями¶
Для оптимальной работы кластера, работающего в режиме растяжения, необходима надежная сеть. Неоптимальная конфигурация сети повлияет на производительность и целостность данных.
- Равномерная задержка между площадками: площадки соединены высокодоступной сетевой инфраструктурой уровня L2 или L3, где задержка между зонами/площадками доступности данных одинакова. В идеале RTT составляет менее 10 мс. Нестабильная сетевая задержка (джиттер) ухудшит производительность кластера.
- Надежная сеть L2/L3 с минимальными пиками задержки : межсайтовое разнообразие путей с резервированием: полная ячеистая сеть или резервный транзит.
- Достаточная пропускная способность : Сеть должна обладать достаточной пропускной способностью для обработки репликации, запросов клиентов и трафика восстановления. Пропускная способность сети должна масштабироваться по мере роста кластера: по мере добавления узлов необходимо также увеличивать пропускную способность межсайтовой сети для поддержания производительности.
- Использование QoS в сети приносит пользу : без QoS шумный сосед, отправляющий или принимающий значительный межсайтовый трафик, может ухудшить стабильность кластера.
- Глобальный балансировщик нагрузки (GLB) : Объектное хранилище, использующее RESTful-конечные точки S3, нуждается в GLB для перенаправления запросов клиентов в случае сбоя сайта.
- Производительность : При каждой операции записи клиент будет испытывать задержку, равную как минимум максимальному значению RTT между площадками. На следующей диаграмме показана задержка работы для кластера из трех площадок с RTT 1,5 мс между площадками, при этом клиент и основной OSD находятся на разных площадках:
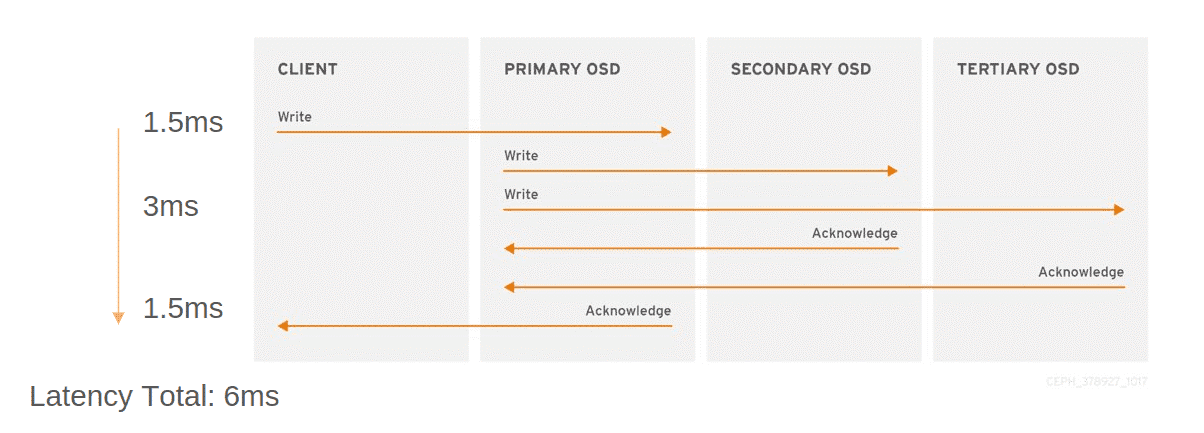
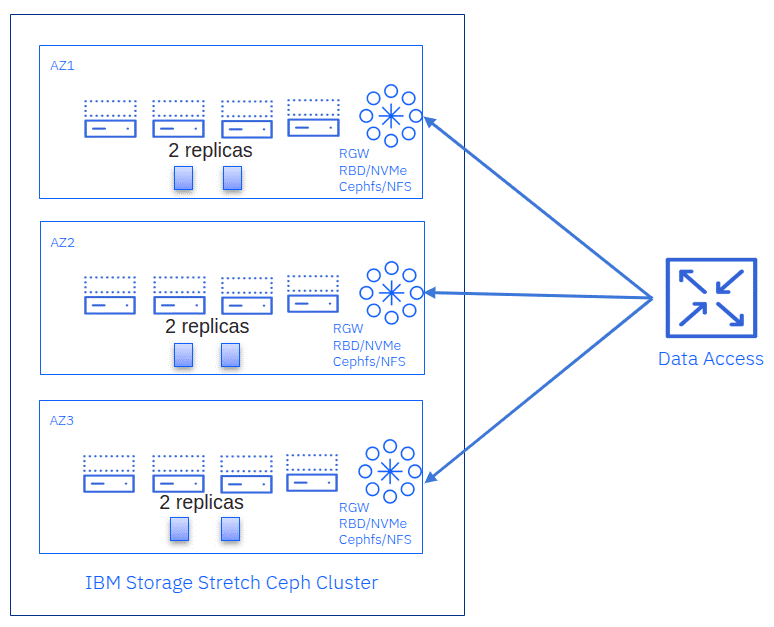
Кластер из трех ЦОД¶
В каждом центре обработки данных (или зоне доступности) размещается часть OSD в кластере из трех площадок. В каждой зоне хранятся две реплики данных, поэтому параметр size пула CRUSH имеет значение 6. Это позволяет кластеру обслуживать клиентские операции без потери или недоступности данных при отключении всей площадки. Ниже приведены некоторые основные моменты:
- Нет возможности разрешить спорную ситуацию : поскольку имеется три полноценных центра обработки данных (OSD на всех площадках), мониторы могут сформировать кворум с любыми двумя площадками, способными связаться друг с другом.
- Повышенная отказоустойчивость : выдерживает полный отказ всего сайта, а также один дополнительный отказ OSD или узла на оставшихся сайтах.
- Требования к сети : рекомендуется маршрутизация уровня L3, а время кругового обхода (RTT) между тремя узлами должно составлять не более 10 мс.
Чтобы подробнее изучить конфигурации растяжения Цефалокона в 3 точках, посмотрите это отличное видео о Ceph от Камолтата Сиривадхны.
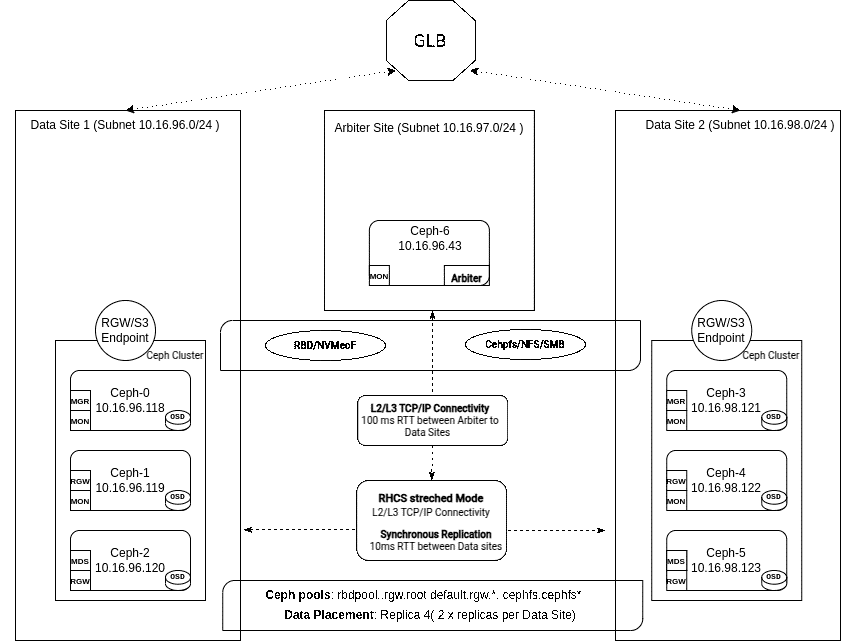
Кластер из двух ЦОД с дополнительным арбитром для определения победителя в случае ничьей¶
Для развертываний, где только два центра обработки данных имеют подключение с низкой задержкой, разместите OSD в этих двух центрах обработки данных, а на третьем сайте разместите монитор, который будет использоваться для разрешения конфликтов. Это может быть даже виртуальная машина у облачного провайдера. Это гарантирует поддержание кворума в кластере в случае отказа одного из сайтов.
- Два основных узла с низкой задержкой : на каждом размещается половина общей мощности OSD.
- Один решающий фактор : хостинг сайта aa, решающий фактор: Монитор.
- Реплики : Стратегия объединения данных replication с параметром
size=4, что означает две реплики на каждый центр обработки данных. - Задержка : Максимум 10 мс RTT между основными центрами обработки данных, содержащими OSD. Центр обработки данных, выполняющий роль посредника, может допускать гораздо большую задержку (например, 100 мс RTT).
- Улучшена обработка разделения сети: предотвращает ситуацию «разделения мозга».
- Требуются OSD-накопители SSD : OSD-накопители HDD не поддерживаются.
Резюме¶
Ceph поддерживает как асинхронные, так и синхронные стратегии репликации, каждая из которых имеет свои компромиссы между целями восстановления, сложностью эксплуатации и требованиями к сети. Асинхронная репликация (зеркалирование RBD, многосайтовая репликация RGW и зеркалирование снимков CephFS) обеспечивает гибкость и простоту географического развертывания, но имеет ненулевое значение RPO. В отличие от этого, растянутый кластер обеспечивает RPO=0 за счет синхронной записи в несколько центров обработки данных, гарантируя отсутствие потери данных, но требуя надежного межсайтового соединения с низкой задержкой и увеличения накладных расходов на репликацию, включая более высокую задержку операций. Независимо от того, выберете ли вы развертывание трех или двух площадок с механизмом разрешения конфликтов, распределенный кластер может бесперебойно справиться с потерей всего центра обработки данных с минимальным вмешательством со стороны оператора. Однако крайне важно учитывать жесткие требования к сети (как к задержке, так и к пропускной способности) и более высокие накладные расходы на емкость репликации size=4. Для критически важных приложений, где непрерывная доступность и нулевой RPO являются первостепенными задачами, дополнительное планирование и ресурсы для распределенного кластера могут оправдать инвестиции. Если приемлем умеренный, но ненулевой RPO, например, если один центр обработки данных предназначен только для архивирования или в качестве резервного центра с пониженной производительностью, асинхронная репликация может быть привлекательной, поскольку на обеих площадках может использоваться эффективное по емкости кодирование с исправлением ошибок.
Два ЦОД и арбитр .. image:: _static/two_dc_arbiter_detailed.png
alt: Два ЦОД и арбитр детальная схема width: 600px align: center
Мы рассмотрели концепции, лежащие в основе стратегий репликации Ceph, подчеркнув преимущества распределенного кластера для достижения нулевой потери данных (RPO=0). Во второй части мы сосредоточимся на практических шагах по развертыванию двухсайтового распределенного кластера с монитором для разрешения конфликтов, используя cephadm. .. image:: _static/stretch_deployment_overview.png
alt: Обзор развертывания растянутого кластера width: 600px align: center
Вопросы, касающиеся сети¶
Сетевая архитектура¶
В архитектуре с расширенным распределением ресурсов сеть играет решающую роль в поддержании общего состояния и производительности кластера.
- Ceph поддерживает маршрутизацию 3-го уровня, обеспечивая связь между серверами и компонентами Ceph в подсетях и сетях CIDR в каждом центре обработки данных/на площадке.
- Автономные или распределенные кластеры Ceph могут быть сконфигурированы с использованием двух различных сетей: - Публичная сеть : используется для связи между всеми клиентами и службами Ceph, включая мониторы, OSD, RGW и другие. - Кластерная сеть : При выделении (опционально) кластер , также известный как репликация , бэкэнд или частная сеть, используется только между OSD для обмена сигналами активности, восстановления и репликации, и поэтому его необходимо выделять только в тех местах, где расположены OSD. Более того, эта опциональная сеть репликации не обязательно должна иметь маршрут по умолчанию (шлюз) к вашей более крупной сети.
Вопросы, касающиеся публичных и кластерных сетей¶
- Единая общедоступная сеть должна быть доступна на всех трех площадках, включая площадку, определяющую приоритет в случае возникновения конфликтов, поскольку все сервисы Ceph зависят от нее.
- Кластерная сеть необходима только для двух площадок, где размещены OSD, и не должна настраиваться на площадке, отвечающей за разрешение конфликтов.
Надежность сети¶
Нестабильное сетевое соединение между узлами OSD приведет к проблемам с доступностью и производительностью кластера.
- Сеть должна быть не только доступна на 100% времени, но и обеспечивать стабильную задержку (низкий уровень дрожания сигнала ).
- Частые скачки задержки могут привести к нестабильности кластеров, влияя на производительность клиентов и вызывая такие проблемы, как нестабильность OSD, потеря кворума монитора и медленные (блокированные) запросы.
Требования к задержке¶
- Допустимое максимальное время кругового обхода сетевого пакета (RTT) между точками передачи данных, где расположены OSD, составляет 10 мс.
- Для решающего сайта допустимо время отклика до 100 мс, его можно развернуть в виде виртуальной машины или у провайдера с высоким уровнем нагрузки, если это позволяют политики безопасности.
Если узел, определяющий исход голосования, находится в облаке или в удаленной сети через глобальную сеть (WAN), рекомендуется следующее:
- Настройте VPN-соединение между сайтами обработки данных и сайтом, определяющим приоритеты в общедоступной сети.
- Включите шифрование при передаче данных с помощью шифрования Ceph Messenger v2, которое обеспечивает безопасность связи между мониторами и другими компонентами Ceph.
Влияние задержки на производительность¶
- В Ceph каждая операция записи обеспечивает строгую согласованность данных. Записанные данные должны быть сохранены на всех настроенных OSD в соответствующем наборе размещения, прежде чем клиент сможет подтвердить успешное выполнение операции.
- Это добавляет, как минимум, время кругового пути (RTT) сети между узлами к задержке каждой операции записи клиента. Обратите внимание, что эти операции репликации ( под-операции ) с основного OSD на вторичные OSD происходят параллельно.
Например, если время отклика между узлами составляет 6 мс, каждая операция записи будет иметь как минимум 6 мс дополнительной задержки из-за репликации между узлами.
Вопросы пропускной способности и восстановления¶
- Ограничения пропускной способности межсайтового соединения: - Максимальная пропускная способность для клиентов. - Скорость восстановления при сбое OSD, узла или сайта, или при последующем восстановлении их доступности.
- При отказе одного узла 67% трафика восстановления будет удаленным, то есть две трети данных будут считываться с OSD на другом узле, потребляя общую межсайтовую пропускную способность наряду с клиентским вводом-выводом.
- Ceph назначает основной OSD для каждой группы размещения (PG). Все операции записи клиента проходят через этот основной OSD, который может находиться в другом центре обработки данных, чем клиент или экземпляр RGW.
Оптимизация операций чтения с помощью функции read_from_local_replica¶
- По умолчанию все операции чтения проходят через основной OSD, что может увеличить задержку между сайтами.
- Эта
read_from_local_replicaфункция позволяет клиентам RGW и RBD считывать данные с реплики, расположенной на том же (локальном) сайте, вместо того, чтобы всегда считывать данные с основного OSD, который с вероятностью 50% находится на другом сайте. - Это минимизирует задержку между сайтами, снижает использование полосы пропускания между сайтами и повышает производительность при выполнении задач с интенсивным чтением.
- Доступно с момента выхода Squid как для блочного (RBD), так и для объектного (RGW) хранилища. Локальное чтение для клиентов CephFS пока не реализовано.
Требования к оборудованию¶
Требования к оборудованию и рекомендации для кластеров с расширенными возможностями идентичны требованиям для традиционных (автономных, не расширенных) развертываний, за некоторыми исключениями, которые будут рассмотрены ниже.
- В режиме растянутого кластера Ceph рекомендуется использовать только флэш-память (SSD). Использование жестких дисков (HDD) для любых ролей в растянутом кластере Ceph не рекомендуется. Вы предупреждены.
- В режиме растяжения Ceph требуется репликация с
size=4использованием политики репликации данных. Кодирование с исправлением ошибок или репликация с меньшим количеством копий не поддерживаются. Планируйте объем хранилища, который вам необходимо выделить, исходя из его исходных и доступных емкостей. - Кластеры с несколькими классами устройств не поддерживаются. Правило CRUSH, содержащее
type replicated class hdd, не будет работать. Если какое-либо правило CRUSH указывает класс устройства (обычно ssd, но потенциально nvme), все правила CRUSH должны указывать этот класс устройства. - Не поддерживаются локальные пулы, не распространяющиеся на другой сайт. То есть ни один из сайтов не может создать пул, который не распространяется на другой сайт.
Размещение компонентов¶
Для устранения единых точек отказа и обеспечения способности кластера выдержать потерю всего сайта без ущерба для доступа клиентов к данным необходимо разместить службы Ceph, включая мониторы, OSD и RGW.
- Мониторы : Требуется как минимум пять мониторов, по два на каждом сайте обработки данных и один на сайте, решающем спорные ситуации. Эта стратегия поддерживает кворум, обеспечивая доступность более 50% мониторов даже при полной недоступности всего сайта.
- Менеджер : На каждом сервере данных можно настроить два или четыре менеджера. Рекомендуется использовать четыре менеджера для обеспечения высокой доступности с парой активный/пассивный режим на оставшемся сервере в случае отказа одного из серверов данных.
- OSD : Распределяются равномерно по площадкам обработки данных. При настройке режима растянутого кластера необходимо создать пользовательские правила CRUSH, разместив по две копии на каждой площадке, всего четыре копии для кластера из двух площадок.
- RGW : Рекомендуется использовать как минимум четыре экземпляра RGW, по два на каждый сервер обработки данных, чтобы обеспечить высокую доступность объектного хранилища с оставшегося сервера в случае сбоя одного из серверов.
- MDS : Минимальное рекомендуемое количество экземпляров CephFS Metadata Server составляет четыре, по два на каждый сайт обработки данных. В случае сбоя одного из сайтов у нас останутся два сервиса MDS на оставшемся сайте: один активный, а другой — резервный.
- NFS : Для обеспечения высокой доступности общей файловой системы в случае отключения одного из сайтов рекомендуется использовать как минимум четыре экземпляра NFS-сервера, по два на каждый сайт обработки данных.
Практическое занятие: развертывание двух центров обработки данных в режиме расширения¶
В процессе начальной загрузки кластера с помощью инструмента развертывания cephadm мы можем использовать YAML-файл определения службы для выполнения большей части конфигурации кластера за один шаг.
Приведённый ниже файл stretched.yaml содержит пример шаблона для развертывания кластера Ceph, настроенного в режиме растянутой конфигурации. Это всего лишь пример, и его необходимо настроить в соответствии с особенностями и потребностями вашей конкретной конфигурации.
service_type: host
addr: ceph-node-00.cephlab.com
hostname: ceph-node-00
labels:
- mon
- osd
- rgw
- mds
location:
root: default
datacenter: DC1
---
service_type: host
addr: ceph-node-01.cephlab.com
hostname: ceph-node-01
labels:
- mon
- mgr
- osd
- mds
location:
root: default
datacenter: DC1
---
service_type: host
addr: ceph-node-02.cephlab.com
hostname: ceph-node-02
labels:
- osd
- rgw
location:
root: default
datacenter: DC1
---
service_type: host
addr: ceph-node-03.cephlab.com
hostname: ceph-node-03
labels:
- mon
- osd
location:
root: default
datacenter: DC2
---
service_type: host
addr: ceph-node-04.cephlab.com
hostname: ceph-node-04
labels:
- mon
- mgr
- osd
- mds
location:
root: default
datacenter: DC2
---
service_type: host
addr: ceph-node-05.cephlab.com
hostname: ceph-node-05
labels:
- osd
- rgw
- mds
location:
root: default
datacenter: DC2
---
service_type: host
addr: ceph-node-06.cephlab.com
hostname: ceph-node-06
labels:
- mon
---
service_type: mon
service_name: mon
placement:
label: mon
spec:
crush_locations:
ceph-node-00:
- datacenter=DC1
ceph-node-01:
- datacenter=DC1
ceph-node-03:
- datacenter=DC2
ceph-node-04:
- datacenter=DC2
ceph-node-06:
- datacenter=DC3
---
service_type: mgr
service_name: mgr
placement:
label: mgr
---
service_type: mds
service_id: cephfs
placement:
label: "mds"
---
service_type: osd
service_id: all-available-devices
service_name: osd.all-available-devices
spec:
data_devices:
all: true
placement:
label: "osd"
После того, как файл спецификации будет настроен для вашего развертывания, выполните команду cephadm bootstrap. Обратите внимание, что мы передаем файл спецификации YAML, --apply-spec stretched.yml, чтобы все службы были развернуты и настроены за один шаг.
# cephadm bootstrap --registry-json login.json --dashboard-password-noupdate --mon-ip 192.168.122.12 --apply-spec stretched.yml --allow-fqdn-hostname
После завершения убедитесь, что кластер распознает все хосты и их соответствующие метки:
# ceph orch host ls
HOST ADDR LABELS STATUS
ceph-node-00 192.168.122.12 _admin,mon,osd,rgw,mds
ceph-node-01 192.168.122.179 mon,mgr,osd
ceph-node-02 192.168.122.94 osd,rgw,mds
ceph-node-03 192.168.122.180 mon,osd,mds
ceph-node-04 192.168.122.138 mon,mgr,osd
ceph-node-05 192.168.122.175 osd,rgw,mds
ceph-node-06 192.168.122.214 mon
Добавьте метку _admin как минимум к одному узлу в каждом центре обработки данных, чтобы можно было выполнять команды Ceph CLI. Таким образом, даже если вы потеряете весь центр обработки данных, вы сможете выполнять команды администрирования Ceph с работающего хоста. Нередко метку назначают _admin всем узлам кластера.
# ceph orch host label add ceph-node-03 _admin
Added label _admin to host ceph-node-03
# ceph orch host label add ceph-node-06 _admin
Added label _admin to host ceph-node-06
# ssh ceph-node-03 ls /etc/ceph
ceph.client.admin.keyring
ceph.conf
Практическое задание: Как Ceph записывает две копии данных на каждый сайт?¶
В режиме растянутой репликации Ceph требует, чтобы все пулы использовали стратегию защиты данных путем репликации size=4. Это означает наличие двух копий данных на каждом сайте, что обеспечивает доступность данных в случае выхода из строя всего сайта.
Ceph использует карту CRUSH для определения места размещения реплик данных. Карта CRUSH логически представляет собой физическую структуру оборудования, организованную в иерархию типов сегментов, которые включают datacenters, rooms, и чаще всего racks, и hosts. Для настройки карты CRUSH в режиме растяжения мы определяем две карты datacenters в корневом сегменте CRUSH по умолчанию, а затем размещаем сегменты хоста в соответствующем datacenter сегменте CRUSH.
В следующем примере показана карта CRUSH в режиме растяжения, включающая два центра обработки данных, DC1 и DC2, в каждом из которых находится по три хоста Ceph OSD. Эта топология получается сразу же, благодаря файлу спецификации, использованному во время начальной загрузки, где мы указываем местоположение каждого хоста на карте CRUSH.
# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.58557 root default
-3 0.29279 datacenter DC1
-2 0.09760 host ceph-node-00
0 hdd 0.04880 osd.0 up 1.00000 1.00000
1 hdd 0.04880 osd.1 up 1.00000 1.00000
-4 0.09760 host ceph-node-01
3 hdd 0.04880 osd.3 up 1.00000 1.00000
7 hdd 0.04880 osd.7 up 1.00000 1.00000
-5 0.09760 host ceph-node-02
2 hdd 0.04880 osd.2 up 1.00000 1.00000
5 hdd 0.04880 osd.5 up 1.00000 1.00000
-7 0.29279 datacenter DC2
-6 0.09760 host ceph-node-03
4 hdd 0.04880 osd.4 up 1.00000 1.00000
6 hdd 0.04880 osd.6 up 1.00000 1.00000
-8 0.09760 host ceph-node-04
10 hdd 0.04880 osd.10 up 1.00000 1.00000
11 hdd 0.04880 osd.11 up 1.00000 1.00000
-9 0.09760 host ceph-node-05
8 hdd 0.04880 osd.8 up 1.00000 1.00000
9 hdd 0.04880 osd.9 up 1.00000 1.00000
Здесь у нас два центра обработки данных, DC1 и DC2. В третьем центре обработки данных DC3 размещается монитор, определяющий исходное решение, ceph-node-06, но в нем не размещаются OSD-устройства. Для достижения нашей цели — наличия двух копий на каждом сайте — мы определяем расширенное правило CRUSH, которое назначается нашим пулам Ceph RADOS.
- Установите пакет
ceph-base, чтобы получить исполняемый файлcrushtool, как показано здесь на системе RHEL.
# dnf -y install ceph-base
- Экспортируйте карту CRUSH в бинарный файл.
# ceph osd getcrushmap > crush.map.bin
- Декомпилируйте карту CRUSH в текстовый файл.
# crushtool -d crush.map.bin -o crush.map.txt
- Отредактируйте файл
crush.map.txt, добавив в конец новое правило, убедившись, что числовой атрибутidправила должен быть уникальным:
rule stretch_rule {
id 1
type replicated
step take default
step choose firstn 0 type datacenter
step chooseleaf firstn 2 type host
step emit
}

- Внедрите расширенную карту CRUSH, чтобы сделать правило доступным для кластера:
# crushtool -c crush.map.txt -o crush2.map.bin
# ceph osd setcrushmap -i crush2.map.bin
- Убедитесь, что новое правило доступно:
# ceph osd crush rule ls
replicated_rule
stretch_rule
Практическое задание: Настройка мониторов для режима растягивания¶
Благодаря нашему файлу спецификации начальной загрузки, мониторы маркируются в соответствии с центром обработки данных, к которому они принадлежат. Эта маркировка гарантирует, что Ceph сможет поддерживать кворум даже в случае сбоя в одном из центров обработки данных. В таких случаях монитор, разрешающий конфликты, действует DC3 совместно с мониторами и оставшимся центром обработки данных для поддержания кворума мониторов кластера.
# ceph mon dump | grep location
0: [v2:192.168.122.12:3300/0,v1:192.168.122.12:6789/0] mon.ceph-node-00; crush_location {datacenter=DC1}
1: [v2:192.168.122.214:3300/0,v1:192.168.122.214:6789/0] mon.ceph-node-06; crush_location {datacenter=DC3}
2: [v2:192.168.122.138:3300/0,v1:192.168.122.138:6789/0] mon.ceph-node-04; crush_location {datacenter=DC2}
3: [v2:192.168.122.180:3300/0,v1:192.168.122.180:6789/0] mon.ceph-node-03; crush_location {datacenter=DC2}
4: [v2:192.168.122.179:3300/0,v1:192.168.122.179:6789/0] mon.ceph-node-01; crush_location {datacenter=DC1}
При работе кластера с тремя площадками асимметричная сетевая ошибка влияет только на связь между одной и второй площадками. Это может привести к шторму неразрешимых выборов монитора, когда ни один монитор не может быть выбран в качестве лидера. .. image:: _static/monitor_election_storm.png
alt: Шторм выборов мониторов при асимметричной сетевой ошибке width: 600px align: center
Чтобы избежать этой проблемы, мы изменим нашу стратегию выборов с классического подхода на подход, основанный на связности. В режиме связности оцениваются баллы соединений, которые каждый монитор предоставляет своим коллегам, и выбирается монитор с наивысшим баллом. Эта модель специально разработана для обработки разделения сети, или, как его еще называют, разделения сети . Разделение сети может произойти, когда ваш кластер распределен по нескольким центрам обработки данных, и все связи, соединяющие один сайт с другим, теряются.
# ceph mon dump | grep election_strategy
election_strategy: 1
# ceph mon set election_strategy connectivity
# ceph mon dump | grep election_strategy
election_strategy: 3
Проверить результаты монитора можно с помощью команды следующего вида:
# ceph daemon mon.{name} connection scores dump
Чтобы узнать больше о стратегии проведения выборов в рамках программы Monitor по обеспечению связи, посмотрите это отличное видео от Грега Фарнума. Дополнительная информация также доступна здесь .
Практическое занятие: Включение режима Ceph Stretch Mode¶
Для перехода в режим растяжения выполните следующую команду:
# ceph mon enable_stretch_mode ceph-node-06 stretch_rule datacenter
Где:
- ceph-node-06 — это монитор, выполняющий функцию арбитра (разрешающего споры) в DC3.
- stretch_rule — это правило CRUSH, которое обеспечивает наличие двух копий в каждом центре обработки данных.
- datacenter — это наша зона риска.
Проверьте обновленную конфигурацию MON:
# ceph mon dump
epoch 20
fsid 90441880-e868-11ef-b468-52540016bbfa
last_changed 2025-02-11T14:44:10.163933+0000
created 2025-02-11T11:08:51.178952+0000
min_mon_release 19 (squid)
election_strategy: 3
stretch_mode_enabled 1
tiebreaker_mon ceph-node-06
disallowed_leaders ceph-node-06
0: [v2:192.168.122.12:3300/0,v1:192.168.122.12:6789/0] mon.ceph-node-00; crush_location {datacenter=DC1}
1: [v2:192.168.122.214:3300/0,v1:192.168.122.214:6789/0] mon.ceph-node-06; crush_location {datacenter=DC3}
2: [v2:192.168.122.138:3300/0,v1:192.168.122.138:6789/0] mon.ceph-node-04; crush_location {datacenter=DC2}
3: [v2:192.168.122.180:3300/0,v1:192.168.122.180:6789/0] mon.ceph-node-03; crush_location {datacenter=DC2}
4: [v2:192.168.122.179:3300/0,v1:192.168.122.179:6789/0] mon.ceph-node-01; crush_location {datacenter=DC1}
Ceph категорически запрещает монитору, определяющему исход спорных ситуаций, занимать роль лидера. Единственная цель этого монитора — обеспечить дополнительный голос для поддержания кворума в случае отказа одного из основных узлов, предотвращая сценарий разделения кластера. По своей конструкции он находится в отдельной, часто меньшей среде (возможно, в виртуальной машине облака) и может иметь более высокую задержку сети и меньше ресурсов. Разрешение ему стать лидером может подорвать производительность и согласованность. Поэтому Ceph помечает монитор, определяющий исход спорных ситуаций, как «неактивный» disallowed_leader, гарантируя, что узлы данных сохраняют основной контроль над кластером, одновременно получая выгоду от голосования за кворум, проводимого монитором, определяющим исход спорных ситуаций.
Практическое задание: Проверка репликации и размещения пула при включенном режиме растягивания¶
При включении режима растягивания демоны объектного хранилища (OSD) будут активировать группы размещения (PG) только при наличии пиринговых связей между центрами обработки данных, при условии доступности обеих групп. Действуют следующие ограничения:
- Количество реплик (атрибут
sizeкаждого пула) увеличится с заданного по умолчанию значения 3 до 4, при этом ожидается наличие двух копий на каждом узле. - Разрешено подключать OSD-устройства только к мониторам, расположенным в том же центре обработки данных.
- Новые мониторы не могут присоединиться к кластеру, если не указано их местоположение.
# ceph osd pool ls detail
pool 1 '.mgr' replicated size 4 min_size 2 crush_rule 1 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 199 lfor 199/199/199 flags hashpspool stripe_width 0 pg_num_max 32 pg_num_min 1 application mgr read_balance_score 12.12
pool 2 'rbdpool' replicated size 4 min_size 2 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 199 lfor 199/199/199 flags hashpspool,selfmanaged_snaps stripe_width 0 application rbd read_balance_score 3.38
Проверьте группы размещения (PG) для конкретного идентификатора пула и подтвердите, какие OSD входят в набор действующих устройств:
# ceph pg dump pgs_brief | grep 2.c
dumped pgs_brief
2.c active+clean [2,3,6,9] 2 [2,3,6,9] 2
В этом примере PG 2.c имеет OSD 2 и 3 от DC1, а также OSD 6 и 9 от DC2.
Вы можете подтвердить местоположение этих OSD с помощью команды ceph osd tree:
# ceph osd tree | grep -Ev '(osd.1|osd.7|osd.5|osd.4|osd.0|osd.8)'
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.58557 root default
-3 0.29279 datacenter DC1
-2 0.09760 host ceph-node-00
-4 0.09760 host ceph-node-01
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-5 0.09760 host ceph-node-02
2 hdd 0.04880 osd.2 up 1.00000 1.00000
-7 0.29279 datacenter DC2
-6 0.09760 host ceph-node-03
6 hdd 0.04880 osd.6 up 1.00000 1.00000
-8 0.09760 host ceph-node-04
-9 0.09760 host ceph-node-05
9 hdd 0.04880 osd.9 up 1.00000 1.00000
Здесь каждый PG имеет две копии внутри DC1 и две внутри DC2, что является ключевой концепцией режима растяжения.
Восстановление сбоев кластера .. image:: _static/stretch_failure_recovery_overview.png
alt: Обзор восстановления после сбоя в растянутом кластере width: 600px align: center
Ранее мы рассмотрели практическое развертывание двухсайтового кластера Ceph с сайтом-решателем конфликтов и монитором, используя пользовательский файл определения службы, правила CRUSH и размещение служб. В этой заключительной части мы протестируем данную конфигурацию, рассмотрев, что произойдет, если выйдет из строя весь центр обработки данных. .. image:: _static/stretch_failure_scenario.png
alt: Сценарий отказа ЦОД в растянутом кластере width: 600px align: center
Введение¶
Ключевой задачей любой кластерной архитектуры с двумя площадками является обеспечение полной работоспособности приложений даже в случае отключения одного из центров обработки данных. Благодаря синхронной репликации кластер может прозрачно обрабатывать запросы клиентов, поддерживая целевую точку восстановления (RPO) равной нулю и предотвращая потерю данных даже при полном отказе одной из площадок. Далее мы рассмотрим, как Ceph автоматически обнаруживает и изолирует неисправный центр обработки данных. Кластер переходит в режим с пониженной производительностью (stretch degraded mode) , при этом монитор, определяющий порядок разрешения конфликтов, обеспечивает кворум. В это время ограничения репликации временно корректируются, чтобы поддерживать доступность сервисов на оставшемся сайте. После восстановления работы автономного центра обработки данных мы продемонстрируем, как кластер плавно восстанавливает свою полную конфигурацию, обеспечивая полную избыточность и синхронизацию без ручного вмешательства. В ходе этого процесса конечные пользователи и администраторы хранилищ будут испытывать минимальные сбои и нулевую потерю данных.
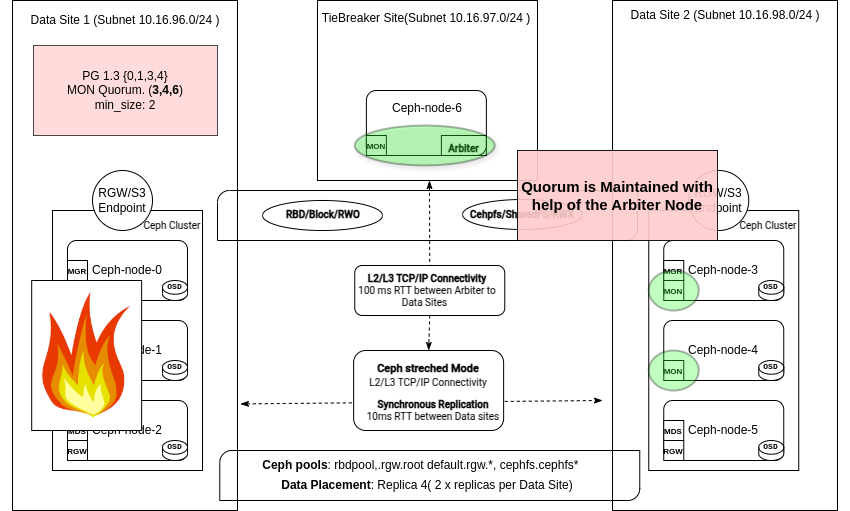
Мы потеряли целый центр обработки данных!¶
Кластер работает как положено, наши мониторы находятся в кворуме, а в состав группы обработки запросов входят четыре OSD, по два с каждого сайта. Наши пулы настроены с использованием правил репликации , size=4 и min_size=2.
# ceph -s
cluster:
id: 90441880-e868-11ef-b468-52540016bbfa
health: HEALTH_OK
services:
mon: 5 daemons, quorum ceph-node-00,ceph-node-06,ceph-node-04,ceph-node-03,ceph-node-01 (age 43h)
mgr: ceph-node-01.osdxwj(active, since 10d), standbys: ceph-node-04.vtmzkz
osd: 12 osds: 12 up (since 10d), 12 in (since 2w)
data:
pools: 2 pools, 33 pgs
objects: 23 objects, 42 MiB
usage: 1.4 GiB used, 599 GiB / 600 GiB avail
pgs: 33 active+clean
# ceph quorum_status --format json-pretty | jq .quorum_names
[
"ceph-node-00",
"ceph-node-06",
"ceph-node-04",
"ceph-node-03",
"ceph-node-01"
]
# ceph pg map 2.1
osdmap e264 pg 2.1 (2.1) -> up [1,3,9,11] acting [1,3,9,11]
# ceph osd pool ls detail | tail -2
pool 2 'rbdpool' replicated size 4 min_size 2 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 199 lfor 199/199/199 flags hashpspool,selfmanaged_snaps stripe_width 0 application rbd read_balance_score 3.38
Для каждого этапа мы представим диаграмму, описывающую различные метки, используемые при возникновении сбоя. В этот момент происходит нечто неожиданное, и мы теряем доступ ко всем узлам в DC1: .. image:: _static/stretch_dc1_failure.png
alt: Потеря доступа к ЦОД DC1 width: 600px align: center
Вот выдержка из журналов мониторинга на одном из оставшихся сайтов: Мониторы DC1 рассматриваются down и удаляются из кворума:
2025-02-18T14:14:22.206+0000 7f05459fc640 0 log_channel(cluster) log [WRN] : [WRN] MON_DOWN: 2/5 mons down, quorum ceph-node-06,ceph-node-04,ceph-node-03
2025-02-18T14:14:22.206+0000 7f05459fc640 0 log_channel(cluster) log [WRN] : mon.ceph-node-00 (rank 0) addr [v2:192.168.122.12:3300/0,v1:192.168.122.12:6789/0] is down (out of quorum)
2025-02-18T14:14:22.206+0000 7f05459fc640 0 log_channel(cluster) log [WRN] : mon.ceph-node-01 (rank 4) addr [v2:192.168.122.179:3300/0,v1:192.168.122.179:6789/0] is down (out of quorum)
Наблюдатель, участвующий ceph-node-03 в DC2, призывает к проведению выборов наблюдателя, выдвигает свою кандидатуру и принимается на пост нового лидера:
2025-02-18T14:14:33.087+0000 7f0548201640 0 log_channel(cluster) log [INF] : mon.ceph-node-03 calling monitor election
2025-02-18T14:14:33.087+0000 7f0548201640 1 paxos.3).electionLogic(141) init, last seen epoch 141, mid-election, bumping
2025-02-18T14:14:38.098+0000 7f054aa06640 0 log_channel(cluster) log [INF] : mon.ceph-node-03 is new leader, mons ceph-node-06,ceph-node-04,ceph-node-03 in quorum (ranks 1,2,3)
Каждый OSD Ceph отправляет сигналы подтверждения активности другим OSD с произвольными интервалами менее шести секунд. Если другой OSD не отправляет сигнал подтверждения активности в течение 20-секундного льготного периода, проверяющий OSD считает его неактивным down и сообщает об этом монитору, который затем обновляет карту кластера.
По умолчанию, прежде чем мониторы подтвердят сбой, два OSD с разных хостов должны сообщить мониторам о неисправности другого OSD. Это помогает предотвратить ложные срабатывания, нестабильность и каскадные проблемы. Однако все сообщающие OSD могут находиться в стойке с неисправным коммутатором, влияющим на связь с другими OSD. Чтобы избежать ложных срабатываний, мы рассматриваем сообщающие узлы как потенциальный подкластер, испытывающий проблемы.
На уровне поддерева отчетов OSD мониторов узлы объединяются в подкластер на основе их общего типа предка в карте CRUSH. По умолчанию для объявления OSD неработоспособным требуется два отчета из разных поддеревьев.
2025-02-18T14:14:29.233+0000 7f0548201640 1 mon.ceph-node-03@3(leader).osd e264 prepare_failure osd.0 [v2:192.168.122.12:6804/636515504,v1:192.168.122.12:6805/636515504] from osd.10 is reporting failure:1
2025-02-18T14:14:29.235+0000 7f0548201640 0 log_channel(cluster) log [DBG] : osd.0 reported failed by osd.10
2025-02-18T14:14:31.792+0000 7f0548201640 1 mon.ceph-node-03@3(leader).osd e264 we have enough reporters to mark osd.0 down
2025-02-18T14:14:31.844+0000 7f054aa06640 0 log_channel(cluster) log [WRN] : Health check failed: 2 osds down (OSD_DOWN)
2025-02-18T14:14:31.844+0000 7f054aa06640 0 log_channel(cluster) log [WRN] : Health check failed: 1 host (2 osds) down (OSD_HOST_DOWN)
В выводе команды ceph status видно, что кворум поддерживается группами ceph-node-06, ceph-node-04 и ceph-node-03:
# ceph -s | grep mon
2/5 mons down, quorum ceph-node-06,ceph-node-04,ceph-node-03
mon: 5 daemons, quorum ceph-node-06,ceph-node-04,ceph-node-03 (age 10s), out of quorum: ceph-node-00, ceph-node-01
С помощью команды ceph osd tree мы видим, что OSD-файлы DC1 помечены как down:
# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.58557 root default
-3 0.29279 datacenter DC1
-2 0.09760 host ceph-node-00
0 hdd 0.04880 osd.0 down 1.00000 1.00000
1 hdd 0.04880 osd.1 down 1.00000 1.00000
-4 0.09760 host ceph-node-01
3 hdd 0.04880 osd.3 down 1.00000 1.00000
7 hdd 0.04880 osd.7 down 1.00000 1.00000
-5 0.09760 host ceph-node-02
2 hdd 0.04880 osd.2 down 1.00000 1.00000
5 hdd 0.04880 osd.5 down 1.00000 1.00000
-7 0.29279 datacenter DC2
-6 0.09760 host ceph-node-03
4 hdd 0.04880 osd.4 up 1.00000 1.00000
6 hdd 0.04880 osd.6 up 1.00000 1.00000
-8 0.09760 host ceph-node-04
10 hdd 0.04880 osd.10 up 1.00000 1.00000
11 hdd 0.04880 osd.11 up 1.00000 1.00000
-9 0.09760 host ceph-node-05
8 hdd 0.04880 osd.8 up 1.00000 1.00000
9 hdd 0.04880 osd.9 up 1.00000 1.00000
Ceph выдает предупреждение OSD_DATACENTER_DOWN о состоянии системы, когда выходит из строя весь сайт. Это означает, что один из серверов CRUSH datacenter недоступен из-за сбоя сети, отключения электроэнергии или другой проблемы. Из журналов монитора:
2025-02-18T14:14:32.910+0000 7f054aa06640 0 log_channel(cluster) log [WRN] : Health check failed: 1 datacenter (6 osds) down (OSD_DATACENTER_DOWN)
То же самое мы видим и из команды ceph status.
# ceph -s
cluster:
id: 90441880-e868-11ef-b468-52540016bbfa
health: HEALTH_WARN
3 hosts fail cephadm check
We are missing stretch mode buckets, only requiring 1 of 2 buckets to peer
2/5 mons down, quorum ceph-node-06,ceph-node-04,ceph-node-03
1 datacenter (6 osds) down
6 osds down
3 hosts (6 osds) down
Degraded data redundancy: 46/92 objects degraded (50.000%), 18 pgs degraded, 33 pgs undersized
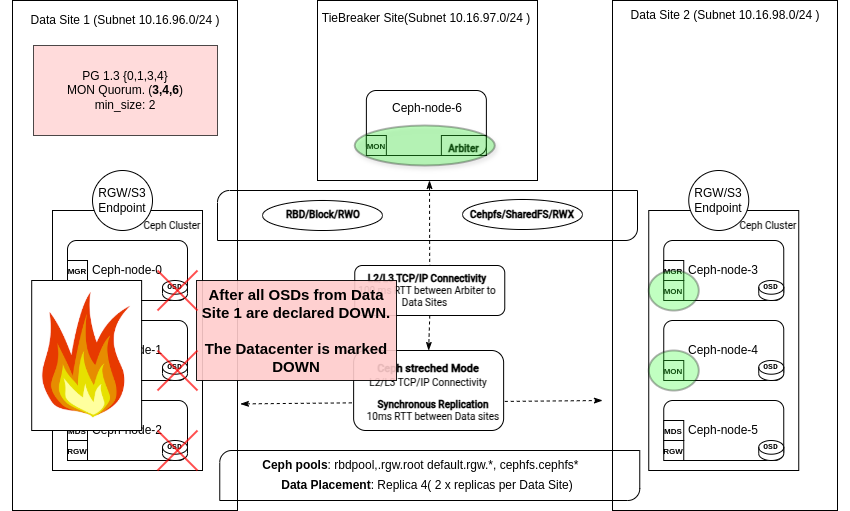
При отказе всего центра обработки данных в сценарии с расширением сети на два площадки Ceph переходит в режим снижения производительности (stretch degraded mode). В журнале Monitor вы увидите запись следующего вида:
2025-02-18T14:14:32.992+0000 7f05459fc640 0 log_channel(cluster) log [WRN] : Health check failed: We are missing stretch mode buckets, only requiring 1 of 2 buckets to peer (DEGRADED_STRETCH_MODE)
Режим растяжения с ухудшением характеристик¶
Режим пониженной производительности с автоматическим управлением активируется, когда мониторы подтверждают недоступность всего центра обработки данных CRUSH. Администраторам не нужно вручную повышать или понижать статус какого-либо сайта или центра обработки данных. Оркестратор Ceph автоматически обновляет карту OSD и состояния групп ресурсов. Как только кластер переходит в режим пониженной производительности с автоматическим управлением, действия выполняются автоматически. Режим Stretch degraded означает, что Ceph больше не требует подтверждения от отключенных OSD в вышедшем из строя центре обработки данных для завершения записи или для перевода групп размещения (PG) в активное состояние. .. image:: _static/stretch_degraded_mode_diagram.png
alt: Диаграмма режима деградации растянутого кластера width: 600px align: center
Правило пиринга в режиме растяжения смягчено¶
В режиме растяжения Ceph реализует специальное правило пиринга, которое требует участия как минимум одного OSD с каждого сайта в действующем наборе, прежде чем группа размещения (PG) сможет перейти из режима пиринга в режим без пиринговых соединений active+clean. Это правило гарантирует, что новые операции записи не будут подтверждены, если один из сайтов полностью отключен, тем самым предотвращая сценарии разделения сети и обеспечивая согласованную репликацию сайтов.
В режиме пониженной производительности Ceph временно изменяет правило CRUSH таким образом, что для активации групп безопасности требуется только работающий сайт, что позволяет бесперебойно продолжать работу клиентских приложений.
# ceph pg dump pgs_brief | grep 2.11
dumped pgs_brief
2.11 active+undersized+degraded [8,11] 8 [8,11] 8
Минимальный размер всех пулов уменьшен до 1¶
Когда один из сайтов отключается, Ceph автоматически понижает значение атрибута пула min_size с 2 до 1, позволяя каждой группе размещения (PG) оставаться активной и чистой, имея только одну доступную реплику. Если бы значение min_size оставалось равным 2, оставшийся сайт не смог бы поддерживать активные группы размещения после потери половины своих локальных реплик, что привело бы к зависанию клиентского ввода-вывода. Временно снижая значение min_size до 1, Ceph гарантирует, что кластер сможет выдержать сбой OSD на оставшемся сайте и продолжит обслуживать операции чтения/записи до тех пор, пока отключенный сайт не вернется в рабочее состояние.
Важно отметить, что временный запуск min_size=1 означает, что до восстановления работы недоступного сайта должна быть доступна только одна копия данных. Хотя это поддерживает работоспособность сервиса, это также увеличивает риск потери данных в случае дополнительных сбоев на работающем сайте. Кластер Ceph с SSD-накопителями обеспечивает быстрое восстановление и минимизирует риск недоступности или потери данных при отказе дополнительных компонентов во время stretch degraded работы.
# ceph osd pool ls detail
pool 1 '.mgr' replicated size 4 min_size 1 crush_rule 1 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 302 lfor 302/302/302 flags hashpspool stripe_width 0 pg_num_max 32 pg_num_min 1 application mgr read_balance_score 11.76
pool 2 'rbdpool' replicated size 4 min_size 1 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 302 lfor 302/302/302 flags hashpspool,selfmanaged_snaps stripe_width 0 application rbd read_balance_score 2.62
Для всех групп безопасности, у которых выйдет из строя основной OSD, в работе клиентских приложений будет наблюдаться кратковременный сбой до тех пор, пока не будут объявлены затронутые OSD down и не будет изменен набор действующих устройств в соответствии с режимом расширения.
Клиенты продолжают чтение и запись данных из двух копий, сохранившихся на работающем сайте, обеспечивая доступность сервиса и RPO=0 для всех операций записи.
Восстановление после режима деградации вследствие растяжения¶
Когда отключенный центр обработки данных возобновляет работу, его OSD-серверы снова подключаются к кластеру, и Ceph автоматически переходит из режима пониженной нагрузки в режим полной нагрузки. Этот процесс включает в себя восстановление и заполнение для восстановления правильного количества реплик в каждой группе размещения (PG) до 4.
Когда OSD имеет действительные журналы PG (и отключен лишь на короткое время), Ceph выполняет инкрементальное восстановление, копируя только новые обновления с других реплик. Когда OSD отключены на длительное время, и журналы PG не содержат полного набора дельта-изменений, Ceph инициирует операцию заполнения OSD для копирования всего PG. Это систематически сканирует все объекты RADOS в авторитетных репликах и обновляет восстанавливающиеся OSD изменениями, произошедшими во время их недоступности.
Восстановление и заполнение резерва требуют дополнительных операций ввода-вывода, поскольку данные передаются между площадками для восстановления полной избыточности. Именно поэтому учет пропускной способности восстановления в расчетах и планировании сети имеет важное значение. Ceph разработан таким образом, чтобы ограничивать эти операции с помощью настраиваемых параметров восстановления/заполнения резерва в mClock, чтобы не перегружать операции ввода-вывода клиентов. Мы хотим HEALTH_OK как можно быстрее восстановить данные, чтобы обеспечить их доступность и надежность, поэтому адекватная пропускная способность между площадками имеет решающее значение.
Это означает не только пропускную способность для ежедневных операций чтения и записи, но и для пиковых нагрузок при отказе компонентов или расширении кластера.
После завершения восстановления или заполнения всех затронутых групп ресурсов (PG) они возвращаются в исходное состояние active+clean с двумя необходимыми актуальными копиями, доступными для каждого сайта. Затем Ceph отменяет временные изменения, внесенные в режиме пониженной производительности (например, min_size=1 возвращается к стандартному состоянию min_size=2). Предупреждение о режиме пониженной производительности кластера исчезает после завершения процесса, сигнализируя о восстановлении полной избыточности.
Краткая демонстрация сбоя и восстановления сайта¶
В этой короткой демонстрации мы запускаем приложение, которое постоянно выполняет операции чтения и записи из блочного тома RBD. Синие и зеленые точки показывают операции чтения и записи приложения, а также задержку. Слева и справа на панели мониторинга отображается состояние контроллеров домена, а отдельные серверы отображаются как недоступные, когда они не работают. В демонстрации мы видим, как мы теряем весь сайт, и наше приложение сообщает всего о 27 секундах задержки ввода-вывода: времени, необходимом для обнаружения и подтверждения сбоя OSD. После восстановления сайта мы видим, что PG восстанавливаются с использованием реплик на оставшемся сайте.
Основные ссылки¶
Дополнительные ссылки¶
- https://docs.redhat.com/en/documentation/red_hat_ceph_storage/5/html/administration_guide/stretch-clusters-for-ceph-storage
- https://ceph.io/en/news/blog/2025/rgw-multisite-replication_part1/
- https://ceph.io/en/news/blog/2025/rgw-multisite-replication_part2/
- https://ceph.io/en/news/blog/2025/rgw-multisite-replication_part3/
- https://ceph.io/en/news/blog/2025/rgw-multisite-replication_part4/
- https://ceph.io/en/news/blog/2025/rgw-multisite-replication_part5/
- https://ceph.io/en/news/blog/2025/rgw-multisite-replication_part6/
- https://ceph.io/en/news/blog/2025/rgw-multisite-replication_part7/
- https://ceph.io/en/news/blog/2025/rgw-multisite-replication_part8/
- https://habr.com/ru/companies/runity/articles/921288/